2021牛客多校第七场复盘
条评论前言
复盘
F - xay loves trees
如果知道怎么用Dfs序维护没有祖先关系或许就是模板题了,不过我是第一次做这种题目…
题意:给定两棵树,两棵树节点一一对应。要求在第一棵树上选择一条链,第二棵树上对应的点中任何两点没有祖先关系,问最多能够选择多少个点?
本题的关键是把没有祖先关系这一点对应到$dfs$序上面。我们可以在$dfs$序上建立一颗线段树,然后当某个点加入被选择的集合中时,对以该点为根的子树的所有点的值$+1$(对$dfs$序,就是在一段连续的区间上进行一次区间加法)。
那么,只要整个区间的最大值为$1$,就代表第二棵树上任意两点都没有祖先关系。
而后,对第一棵树,只需要$dfs$每一条可能的链,判断第二棵树上有无出现非法情况,并设置一个栈用于回滚区间加操作的影响,就能完成该题。
感觉这道题代码可以作为模板使用了,写的真不戳
1 | /* vegetable1024 | liushan.site | Maybe Lovely? */ |
H - xay loves count
签到题。
设置一个桶统计每个数字出现的次数,然后枚举每个数以及它的倍数即可。
复杂度计算与调和级数相同,为$O(nlogn)$。
1 | /* vegetable1024 | liushan.site | Maybe Lovely? */ |
I - xay loves or
签到题,考察细节…
主要是判断每一位取$1$和取$0$的可能性,并且要保证$1 \leq x < s \leq 2^{31}$,也就是$s$不能全$0$。
1 | /* vegetable1024 | oi-liu.com | Maybe Lovely? */ |
J - xay loves Floyd
涨知识了,之前确实不知道这样写会出错,不过据说不论顺序,只要运行三次就都是对的(
第一次做跟$bitset$相关的题目,感觉这个优化真的狗(
首先由$n, m$判断,本题在$n$很大时是个经典的稀疏图,因此可以用$Dijkstra$,以每一个点为原点,建立正确的最短路关系,这一步复杂度为$O(nmlogm)$。
有了正确的最短路关系后,我们考虑按照题目的枚举顺序,要怎么样才能够获得正确的答案。
这里可以参考一下题解,讲的很清楚:
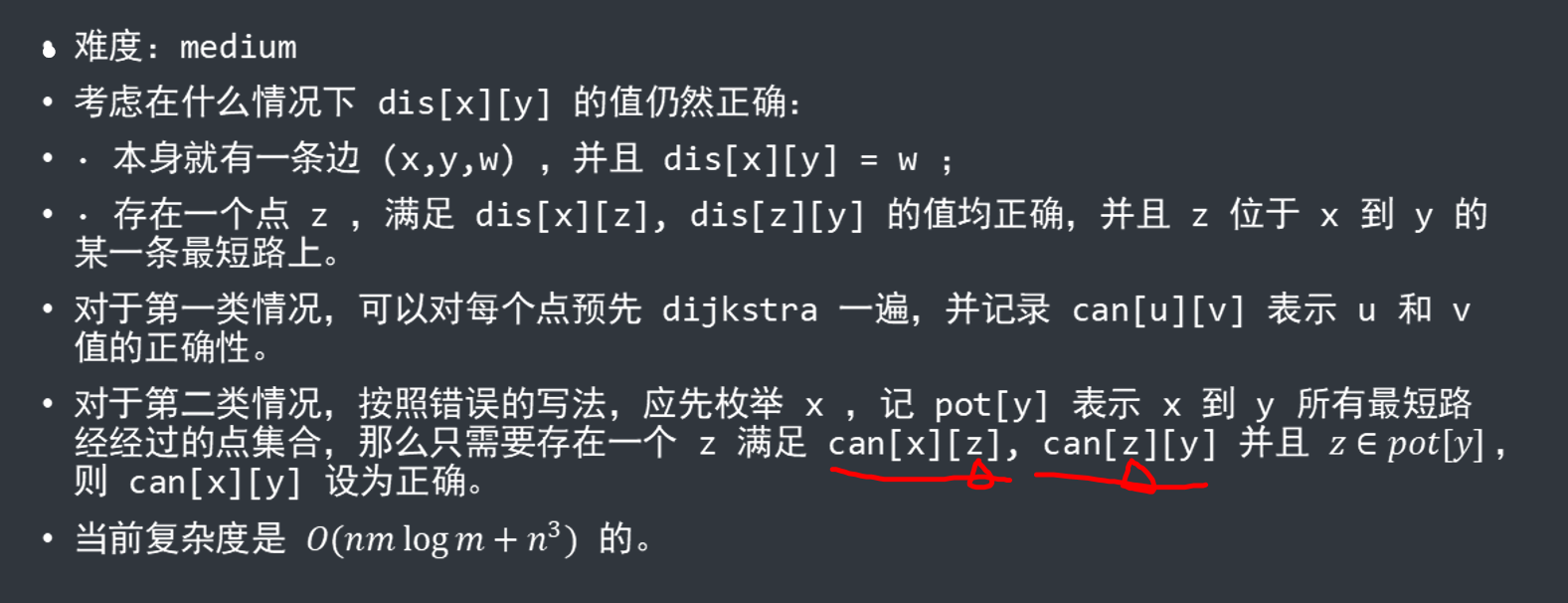
但是$O(n^3)$的复杂度是难以通过这题的,我们需要更优秀的算法。
考虑$bitset$优化,对于$can[x][z], can[z][y]$,我们改写为$bitset\langle X \rangle f[x], g[y]$。
此时$f[x][i]=1 \leftrightarrow can[x][i] = 1$,但是在计算的时候有了常数优化,一般为$/32$或者$/64$。
最初的时候,我们对其赋初值$f[x][x]=1,g[y][y]=1$,代表自己到达自己是合法的。
而对于本身就存在一条边是最短的情况,同样赋值$f[u][v]=g[v][u]=1$,到此就可以开始模拟$Floyd$了。
首先我们枚举$s = 1\dots n$,此处$s$同$x$,为起点之意。
在枚举的过程中,为了进一步从$f[x][z],g[y][z]$推导到$f[x][y],g[y][x]$,需要再维护一个最短路所经过的点。
我们可以简单的按照距离排序(也可以按照拓扑序),维护一个$pot[i]$。
当$E[i].w + dis[s][now] = dis[s][E[i].to]$时,就说明所有$s$到$now$的最短路上的点都可以到达$E[i].to$。
即有$pot[E[i].to] |= pot[now]$。
由此,就可以快速处理第二种情况,即枚举每一个$y$,判断$f[x],g[y],pot[y]$有无交集,有则说明该点得到的最短路距离是正确的。
1 | /* vegetable1024 | liushan.site | Maybe Lovely? */ |
题解中还提到另一种更优秀的做法:
